Attached is a first draft of a paper that is pair with another paper in progress.
This paper articulates why the combination of (a) “poverty reduction is the objective of development” and (b) the poverty line used to define and measure global poverty is (or any update of) the WDR 1990 ‘dollar a day’ poverty line is no longer a viable stance for a development organization or actor.
The basic point is that ‘dollar a day’ was always an unreasonably penurious poverty line and now, with the continued economic growth (even where not particularly rapid) nearly all developing countries have reached a point where there are very few ‘dollar a day’ poor. For instance, in the latest World Bank data Pakistan is reported as having only 4.9 percent of its population in the ‘dollar a day’ (which is now P$2.15) or “extreme” poverty. This implies that development actions that produced broad-based benefits in Pakistan would not benefit the “global poor” as only 1 in 20 Pakistanis is “poor.” This is just ridiculous (or perhaps beyond ridiculous, I am not quite sure).
The companion paper, which is underway and co-authored with Martina Viarengo examines the question “what is a plausible global upper bound poverty line?” Whereas ‘dollar a day’ is the answer to the question ‘what is the lowest a global poverty line could be?’, if one is going to use a range of poverty lines (as we argue that one must to have poverty reduction and development be synonymous) then one needs a range, a lower bound (‘dollar a day’) and an upper bound. This paper should be finished soon (in the academic sense of ‘soon’).
There is a very nice blog from June 2023 on the interactions between climate change and poverty on the World Bank Open Data site (based on also very nice recent research papers by the authors (working paper and published version). However, their opening paragraph contains a statement that is, kind of, on the face of it, correct, but, at the same time, can create confusion.
“Eradicating extreme poverty and stopping global warming can only be tackled together: reducing poverty without considering carbon emissions is a self-defeating strategy, as climate change impacts will threaten hardly won development gains. But despite rapid progress to decarbonize the world economy, reducing poverty by increasing people’s consumption today requires increasing carbon emissions, since economic systems in most developing countries still rely on fossil fuel energy. And the eradication of extreme poverty is so urgent that it cannot be delayed, especially to fix a problem that has largely been created by the richest among us.”
The potential confusion here is that this paragraph can be read as implying that for a given country addressing their own poverty that the problems of poverty and carbon emissions must be tackled together. In a direct causal sense, this is just obviously false. That is, take a country with currently high levels of extreme poverty, say, Ethiopia at 27 percent or Malawi at 70 percent. If one is concerned about their levels of extreme poverty to 2050 then it should be clear that, to first order, nothing about Malawi’s own carbon emissions between now and 2050 will have anything to do with the consequences of climate change for Malawi and its poverty. This is because Malawi’s own incremental emissions between now and 2050 under any growth scenario for Malawi are so small relative to the global total stock of carbon in the atmosphere in 2050 that the consequences for Malawi (or any other country) are vanishingly small. This is for three reasons, which are three deep features that make the challenge of climate change so very challenging.
One, carbon stays in the atmosphere a very, very long time and hence much of the relevant stock in 2050 has already been determined by emissions that have already happened. (This feature is in sharp contrast to some, but not all, other environmental challenges where the natural processes can remove pollution such that if the flow goes down the stock can go down.)
Two, Malawi by being both very poor and very small in population has very small total emissions and hence incremental emissions under various feasible growth paths are also very small. So, according to the figures reported in Our World in Data the emissions in 2021 in Malawi were 23.85 million tonnes whereas in the USA they were 5.93 billion tonnes. This means even if Malawi’s emissions were to grow by 50 percent by 2050 this would be the equivalent of a .2 percent (one fifth of one percent) reduction in US emissions. And China’s 2021 emissions are 13.71 billion tonnes.
Three, climate change in a global phenomena and depends on the total global stock and hence all countries are affected by the totals, irrespective of their own emissions. So nothing Malawi does about carbon emissions will have any first order effect on Malawi’s damages from climate change compared to about anything China or the US or Europe or India do.
I think there are three important reasons to make this clear.
First, this aspect of the “sustainability” of economic growth is very different from considerations where the feedback loops are at the country level and hence the default concern was that a given country was using up its own stock of natural resources (e.g. groundwater, forests, fertile soil, fisheries, oil, minerals, etc.) or creating its own environmental damages (e.g. air pollution, water pollution) that these would put a check on future economic production or wellbeing. But these feedbacks loops were national (or perhaps regional) and hence the question was whether the processes of economic growth and wellbeing gains could be sustained or were ignoring the “true” total stock of productive assets of the country, including their natural resources. In this respect climate change is very different as Malawi’s growth/wellbeing prospects may well suffer and become “unsustainable” due to climate change, but this will be because of the past and future actions of others, not (to first order) because of anything Malawi does about its own emissions. (And “Malawi” is just a place holder for “small to medium sized developing country with high extreme poverty). So, from the point of view of a given country there may be much more pressing environmental sustainability issues actually under its more direct policy control than carbon emissions. And, from a country view the actions to mitigate the negative consequences of climate change on their wellbeing might also be much, much, more important than controlling their emissions.
Second, there are enormous legitimate political pressures to dissemble about this. That is, controlling climate change requires many countries to cooperate in lowering their emissions relative to their BAU baseline. But these reductions are a “global public good” and every country understands that their efforts alone are ineffective. So many countries may reasonably say: “I will only cooperate to reduce emissions if all other countries cooperate.” This creates a pressure to get all countries to commit to action on their own emissions. This in turn creates pressures to tell countries: “The consequences for your country of climate change are going to be very bad so you should, as a country, commit to actions to reduce your carbon emissions, at the very least for any given amount of economic growth (e.g. carbon intensity) even if not in absolute terms.” But, while that statement is rhetorical powerful, everyone, not least developing country political leaders and policy makers, can see that it is logically flawed and false, or, at the very least, leaves out the key feedback mechanism working through global politics: “…if you fail to commit to climate actions this may cause other countries, whose emissions in total will really make a difference to climate change, to not take action and these emissions of other countries could make climate change consequences worse in your country.” Improving Malawi’s carbon emissions will only benefit climate conditions in Malawi through an indirect channel of political transmission.
Third, this is especially important for the World Bank, which is seeking to make the “global public good” of climate change more important in its agenda. But this is going to necessitate a tricky change for the World Bank. Previously, if the World Bank (via IDA) was doing projects in Malawi it was usually the case that the costs and benefits of the project were justified exclusively by the costs and benefits to Malawi as, in the end, the World Bank is a Bank and it makes a loan (even if, on IDA terms this has a huge grant element relative to market costs) to Malawi. But if the World Bank is making a loan to Malawi that affects carbon emissions one has to be clear whether this is justified as actions by Malawi based on the costs and benefits just for Malawians or whether part of the justification is that Malawi is making a contribution to the “global public good.” And if the answer is that the actions are contributing to the “global public good” with resources borrowed from a global development agency like the World Bank, what is the appropriate allocation of those incremental costs between the future citizens of Malawi (who have to repay the loan) and the rest of the global population which enjoys the benefits of Malawi’s actions. The tensions here are obvious and the stakes are high and lack of clarity here can undermine in the long-run the World Bank’s legitimacy.
Interestingly, after this introduction claiming “reducing poverty without considering carbon emissions is a self-defeating strategy” the blog, based on real research and actual numbers, makes exactly the opposite point. The incremental carbon emissions to reduce extreme poverty are inconsequentially small. By their calculations the incremental carbon emissions to “eliminate” (drive to 3 percent or less in every country) extreme poverty at historical relationships of GDP growth to poverty and GDP growth to emissions was only 4.9 percent of 2019 levels–which is roughly the amount global emissions have been increasing every three years since 2020. So, however negative the consequences of climate change are in 2050 it almost certainly will not be because countries grew at a pace needed to reduce extreme poverty. Rather what will determine climate change (including on countries with extreme poverty) is whether the countries responsible for nearly all historical and current emissions–and who do not have any appreciable extent of “extreme poverty”–did or did not reduce their emissions. T
This is related to a presentation about “sustained” versus “sustainable” development for a group in Pakistan in 2022, in which I make this point about climate change without the benefit of the more accurate and concrete numbers this recent research provides.
I have been contacted by journalists at times as a “critic” of RCTs. This worries me. My wife, who is a wise woman, has been encouraging me to stop writing and talking about RCTs because I will be seen as a cranky old kook who doesn’t “get it” and doesn’t have anything better to do than nit pick about the work of others.
This blog post is just to clarify that I am “for” things and spend most of my time and research and writing promoting those things. In a sports metaphor, I try and spend most of time playing “offence”–but at times, unfortunately, the best offence is a good defense and in a game like chess, you cannot just pursue your own strategy or you can end up checkmated.
Overall what I am actively “for” has been pretty constant. What I am “for” is that more and more people on the planet have the same opportunities that I have had and the same access to prosperity and safety and security and order and decent schools that I had growing up in the USA in the 1970s as a child of middle class white parents. The expansion of opportunities for people to live a life of their choosing is how I think of the “development” agenda. And, as an economist, I am more about what can be done at the system level to shape the choices people have rather than imagining that I know better and should nudge people about the choices they make.
I regard the “national development” as an instrumental path to raising human wellbeing. National development is a four-fold transformation of countries to have (i) a more productive economy, (ii) a more capable state, (iii) a more responsive polity, and (iv) a more equal treatment of all citizens.
Here are four agendas in research and practice that I have been actively working on (and writing papers about) over the last 20 years or so.
Rapid and sustained growth in broad based labor productivity. I could say “economic growth” but this often raises hackles needlessly as people assume that “economic growth” must always mean “GDP” as currently measured. Like all professional economists I know: (i) don’t regard GDP as a direct measure of wellbeing at all, (ii) acknowledge the many limitations of GDP in measuring and valuing “true” economic output (and in keeping track of “wealth”) and (iii) am more than happy to put more weight on the gains in income/consumption of poorer people than richer people. But, at the same time, GDP per capita turns out to be a handy and available proxy.
Rapid and sustained economic growth is empirically necessary and empirically sufficient for achieving nearly all goals in improving human material wellbeing (including (i) the reduction of standard measures of poverty, (ii) any aggregate of the basics of material wellbeing (e.g. health, education, water and sanitation, child malnutrition), and (iii) (together with state capability) broad based indicators of human wellbeing, including (but not limited to) measures like the Social Progress Index that are exclusively based on non-money metric measures of wellbeing.
Higher levels of state capability. In addition to growth, a second transformation is having high state capability, which I define as having public sector organizations capable of effective implementation of the laws, regulations, policies, programs and projects that advance the legitimate goals of these organizations. In common sense terms this is having police forces that create order and security, education systems that equip kids with the skills and knowledge and capabilities they need, tax agencies that collect taxes without corruption, agencies that produce reliable infrastructure services (e.g. water, power, roads), etc. (And this definition does not resolve any particular “public vs private” debate as the “make vs buy” question of whether the direct producers of services should be public or private organizations does not imply there is no need for “state capability” as contracting out to or regulation of private providers requires state capability).
In “National Development Delivers” I show that both growth and state capability are strongly associated with cross-national human wellbeing measures and the strength of the relationship differs with (i) level of income (growth is more important at lower levels of income than at high levels), (ii) how “basic” the indicator is, with economic growth more important for more basic to wellbeing, and (iii) state capability is more important the more important effective collective action is to achieving good outcomes (e.g. the more it is a “public good”)).
The Building State Capability project at Harvard Kennedy School’s Center for International Development points a useful way forward on this agenda.
Effective education for all. I spent the last 8 years as the Research Director of RISE (Research on Improving Systems of Education) (the project recently ended, as planned, on March 41, 2023). This is part of a larger agenda built around the twin ideas that (i) while countries have been very successful at expanding schooling many countries have very low (and in many cases declining) levels of learning per year of schooling so “schooling” goals are being met while the true “education” objectives of schools are far from being achieved and (ii) accelerating progress in learning is going to require not just “project” tweaks inside “business as usual” but pretty thorough-going “system” reform.
Labor mobility. Given that “national development” doesn’t always happen and even when it happens it often takes a long time, this means that today (and into the foreseeable future) there will be large gaps in the productivity of the same individuals across places and hence there are, at the margin, massive income gains to allowing people to move from low productivity places to high productivity places. I am currently working to promote “more and better” pathways for people to move to opportunity via LaMP (Labor Mobility Partnerships).
I am not arguing these are the only aspects of development that are pressing or needed, there are lots of huge and important elements of the national development agenda that I have not been actively working on (e.g. infrastructure, energy, agriculture, urbanization, gender, law and order/policing, climate change, etc.). Mine are just the four that through my contingent life/professional trajectory I have ended up working on through a some combination of interest, opportunity, and an assessment these topics were “important, neglected, tractable.” And these have kept me very busy and productive as over the last 20 years or so I have written (mostly with co-authors) books, journal articles, papers, blogs, policy briefs on these topics.
Playing defense. That said, in order to promote the national development agenda (both broadly and in the specific domains in which I was active) I have played some defense. From my point of view, a major problem with development organizations and funding is that over the last 30 years or so there have been constant efforts to “define development down“, that is, shift the agenda away from “national development” (that sees the challenge as equal opportunity for people across the planet and hence has expansive, long-term, ambitious goals) to “kinky development” (here) that looks to narrow development to “charity work” by advocating just “low bar” goals in a few sectors (here). Development funding (both official and philanthropic) from the “North” or “West” (neither of which are of course geographically literal as the “North” includes Australia and the “West” includes Japan) has had a tendency, driven by their own domestic politics and needs, not the concerns in developing countries (here ), to shy away from the hard slog of the four-fold transformations and instead look to fund specific (often cocooned from systems and implemented by NGOs to bypass states) project “interventions” that are “effective” and “attributable.” So I have written papers (and blogs and speeches and etc.) arguing: (i) that “dollar a day” poverty is an obscenely low standard (here and here) and “dollar a day” (or other penurious poverty goals) cannot be goals around which a countries can build its development agenda (here); (ii) the Millennium Development Goal for “completing primary school” while ignoring any measure of learning of skills or capabilities was misguided (here and here–and then everywhere in RISE); (iii) that “kinky development” was not a development agenda that met the legitimate and pressing goals and ambitions of the governments and people in “the South” (here and here).
I think it is obvious to most observers that “national development” is the big agenda and “kinky development” is the small agenda. Moreover, it is also pretty clear that even within the “kinky development” agenda the kind of evidence that the “randomista” movement can, even in principle, generate is just one (small?) part of promoting and implementing effective progress even within that limited kinky agenda. So, while this (faith based) movement has been a relatively important part of academic development economics in the West, it is, at best, literally a footnote to the actual development experience.
As a thought experiment, the 13 developing countries with populations over 90 million people, which together account for over three quarters of the developing world population, are: China, India, Indonesia, Pakistan, Brazil, Nigeria, Bangladesh, Mexico, Ethiopia, the Philippines, Egypt, Vietnam, DR Congo. Each of these countries has an interesting, often turbulent, recent economic history, some with amazing success at improving the material wellbeing of their populations, some with mixed results, some catastrophic. Ask yourself: would it be plausible to write a recent history of each these countries, and even a recent economic history, or even of their recent “development” experience without any mention of RCTs or the generation of “rigorous evidence” about specific interventions?
I am for national development, which has an array of important elements within it. Over recent years I have (mostly) been doing research and working on four topics: economic growth, state capability, basic education, and labor mobility. As part of being a proponent of national development and of key issues within that, I have played some defense against the temptations of “kinky development” and, within that, spent some quite small amount of my time trying to play down expectations for what the very visible and very popular randomista agenda could really deliver in practice, on a number of fronts (here and here and here). But this does not make me a “critic”–much less an “enemy” or “opponent” of RCTs–this just makes me a consistent proponent of the effective promotion of national development as a pathway to higher human wellbeing.
Here is what seems like a pretty simple question. You have done an RCT in country X and produced a consistent estimate of the treatment effect of intervention I on outcome O. I am in country Y and have a simple OLS estimate of the partial correlation of I on O. How much should I move my priors from being centered on the OLS estimate from my country to the “rigorous” treatment effect estimate from country X? (And one could extend this to having done N RCTs in N countries that were not country Y).
Not only does this seem like a simple question, it seems like a pretty important question as without an answer to this question one cannot make any claims about the benefit-cost calculations of doing RCT research. If the scope of applicability of the finding isn’t known then, at best, one can only apply the rigorous treatment effect estimate to exactly the conditions in which it was generated–and hence the benefit/cost is likely to be very low (unless the country/program is massive scale).
Unfortunately, the answer to this question is not simple, the “intuitive” answer has very bad properties, and empirically, just using OLS from Y and ignoring the estimate that was rigorous in country X can produce better predictions.
the answer is not simple as an RCT, in principle (and often in practice) produces an OLS estimate and an RCT estimate and hence produces an estimate of the bias in OLS for the true treatment effect in X. This means there are two distinct pieces of “rigorous evidence”: the treatment effect estimate and the OLS bias estimate. Given an existing distribution of OLS estimates it is likely that these will suggest moving the OLS estimate in some countries, Y, in different directions–the treatment effect estimate will suggest the country Y treatment effect should be bigger but the OLS bias estimate will suggest country Y treatment effect should be smaller.
If one says the seemingly intuitive “move the treatment effect estimate for Y to the estimate for X (or to the average of the estimates for the N countries)” this (likely) implies (i) some countries revise their TE estimate upward from OLS and others downward and (ii) that the variance across countries in the true treatment effect goes to zero, even when the OLS estimates have large variance. Neither of these make any sense.
The Root Mean Square Error (RMSE) of the “collapse onto the rigorous estimates” prediction is, in now three empirical examples, larger than just using OLS country by country because the “internal validity” problem solved by RCTs is just so much smaller than the “external validity” problem created with the heterogeneity across countries in the “true” treatment effects.
(That was a new introduction to the following blog)
The attached paper (submitted to a special issue of Review of Development Economics) is a case in point. You would think that, after all the intellectual and financial resources that have gone into RCTs and into the creation of “systematic reviews” that aggregate the “rigorous evidence” there would be a sensible and empirically validated answer to the question: “How should be beliefs about the impact of actions X on outcome Y in my country context, call it C, (LATE(X,Y,C) change in response to a rigorous study (or systematic review of rigorous studies) from other countries/contexts?” But there just isn’t.
And it is easy to point out that things you might think sensible could be said, like: “Beliefs about LATE(X,Y,C) should move from existing the existing non-rigorous estimates in context C towards the findings from rigorous studies” don’t pass muster as being even logically coherent. As Justin Sandefur and I pointed out some years ago since the true LATE(X,Y,C) can be decomposed into the non-rigorous estimate in C and the bias in that estimate, if there is heterogeneity (variance) in the non-rigorous estimates across contexts (and there is) then this generically implies that in response to a systematic review some countries should shift their beliefs towards a larger LATE and some countries towards a lower LATE, which implies that the bias in those cases has a different sign. So any generic advice about adopting the “rigorous evidence” essentially demands people adopt beliefs about bias that are a wildly implausible set of measure zero. That is bad science.
Slightly harder is to point out that adopting as the prediction of LATE(X,Y,C) the systematic review point estimate does empirically worse that just using OLS(X,Y,C) as the prediction of LATE(X,Y,C). This point is stunning. If the heterogeneity in the true LATE across contexts is large relative to the bias in non-rigorous estimation methods then it is the case the most naïve possible thing is actually better than the supposedly new, better, cooler, more “sciency” approach of doing some RCTs in some countries and then aggregating those in a systematic review.
That this is so is harder to point out for two reasons. One, because there are so few RCTs that are even moderately comparable it is hard to have enough estimates of the “true” context specific LATE to create a variance in predictions. Two, because systematic reviews (and the underlying papers) tend to ignore the existing non-rigorous estimates altogether so the question of “how much better?” cannot be answered.
The attached paper solves these problems by using two sources that have comparable estimates of a “raw”, an “OLS” and a “LATE” for the same quantity for a larg(ish) number of countries. The LATE is the Oster estimate using the standard assumptions.
For 42 developing countries there is a Raw, OLS, and LATE(Oster) estimate of the wage gain for a typical low-education level worker moving from their home country to the USA from Clemens, Montenegro and Pritchett (2019).
For 29 developing countries there is a Raw, OLS, and LATE(Oster) estimate of the private sector learning premium from Patel and Sandefur (2020).
Once one has data like this, the rest is easy, just simple arithmetic (hence the temptation of paper arbitrage): compare the Root Mean Square Error (RMSE) of (i) using the average of the LATE estimates (the “systematic review”) to predict the LATE in each country or (ii) use the OLS from each country to estimate its LATE.
As expected, the answer depends on the ratio of the variance of the LATE to the typical bias in OLS. For wage gains the variance is huge and the bias modest so using context specific OLS is twice as good as using the “rigorous evidence.” For the private sector learning premium the variance is modest and the bias substantial (selectivity into private schools is large) and hence OLS and the “rigorous evidence” do about the same in RMSE.
So, for about 25 years now there has been a major advocacy movement selling people on the notion that doing RCTs about specific interventions in specific contexts and then aggregating these was going to lead to “evidence based” policies based on “rigorous evidence” and that would lead to better development outcomes. But there has never been any evidence these claims were true. Moreover, they always seemed pretty improbable and inconsistent with our “best available” models of development phenomena, that suggested that contextual variance in policy outcomes was likely to be very large.
These claims about external validity are not a picayune detail as without some clear idea about the scope of reliability of the results across contexts it is impossible to claim any piece of research, and especially expensive research, like RCTs, are a cost-effective investment.
I was invited to give a talk at George Mason University’s Mercatus Center and the series is about economics but also politics and economics. So I decided to give a seminar on a new paper I have just started working on which is the argument that development economics has been suffering from a “Gresham’s Law” (bad money drives out good) in which bad economics (poverty analysis with low bar poverty lines) has driven out good economics (the use of (inequality averse) social welfare functions. The paper is going to articulate why poverty with low bar poverty lines when used as a development objective or to evaluate policies/programs inevitably makes key mistakes and, moreover, doesn’t satisfy a basic “golden rule” of treating others like you would like to be treated. I argue that low bar poverty lines are both bad economics and also just plain bad–morally bad.
Here is an (ex-post edited) version of the slides that articulates the four key analytical mistakes an analysis using low bar poverty lines makes (all of which are avoided in standard economic welfare measures).
I was recently invited by email to give a keynote address to a conference at the Fatima Jinnah Women University which was the “Second International Conference on Sustainable Development in Contemporary World: Priorities, Challenges and Prospects”
I emailed back arguing that I was no expert in “sustainability” as it is currently commonly construed and gave my arguments and hence they probably should invite someone else. Somewhat to my surprise the inviter was even more adamant and so I ended up giving a talk on October 4, 2022 to an audience in Pakistan via Zoom (which involved me speaking into a camera in the middle of my night).
Here is a video of the entire speech (a little bit over an hour), but wanted to also post the slides from the presentation. I (try) to make four major points:
(i) for developing countries to have sustained improvements in material wellbeing they will need sustained economic growth.
(ii) one needs to make the distinction between “sustained” growth and the causes of economic growth to not be “sustained”–which can be political, conflict, economic policy, global crisis, bad luck, etc.–and whether or not the issues called “sustainable” are likely to be a cause for growth to not be “sustained.” It could be that “sustainability” issues, while real, are a very small subset of the likely challenges to sustained growth over the medium run horizon.
(iii) the prioritization among all sustainability/environmental/natural resource challenges needs a clear basis–and the contribution of natural resources to sustainable development may not be “preservation” but rather wise use.
(iv) and this point seems both obvious to everyone but also rarely articulated, is that whatever one believes about the likely severity of climate change on Pakistan’s prospects for sustainable development (whether unmitigated or optimally mitigated), everyone agrees that, on a technical level, Pakistan’s past, current and future carbon emissions will have little or nothing to do with the impact of climate change on Pakistan (except perhaps by indirect political channels). Even if Pakistan adopted the “greenest” or “lowest GHG emission” economic growth path possible, this is unlikely to have any direct impact on climate change as the externality is global and Pakistan’s emissions are small.
I am posting this well aware that people may argue I proved my original argument: that I should not be giving keynote speeches at conferences about sustainable development, but I did and so there’s that.
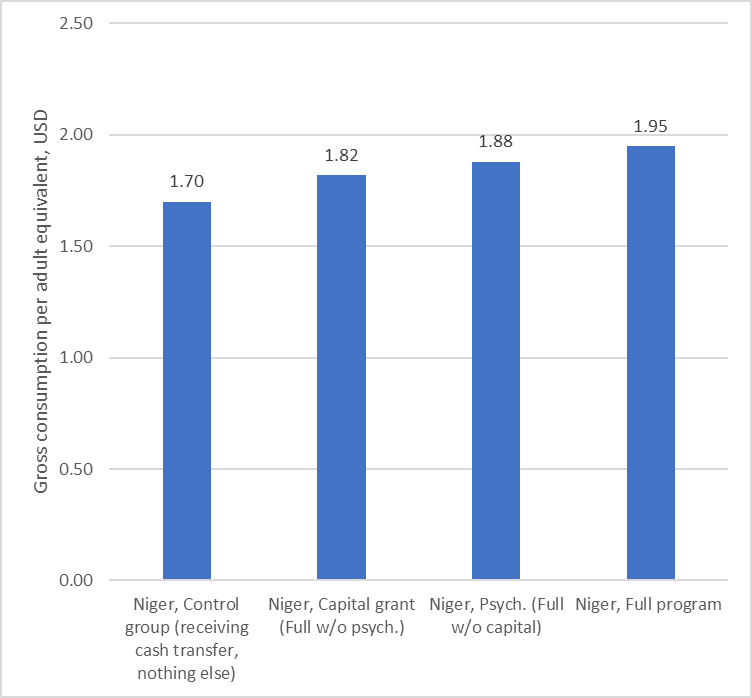
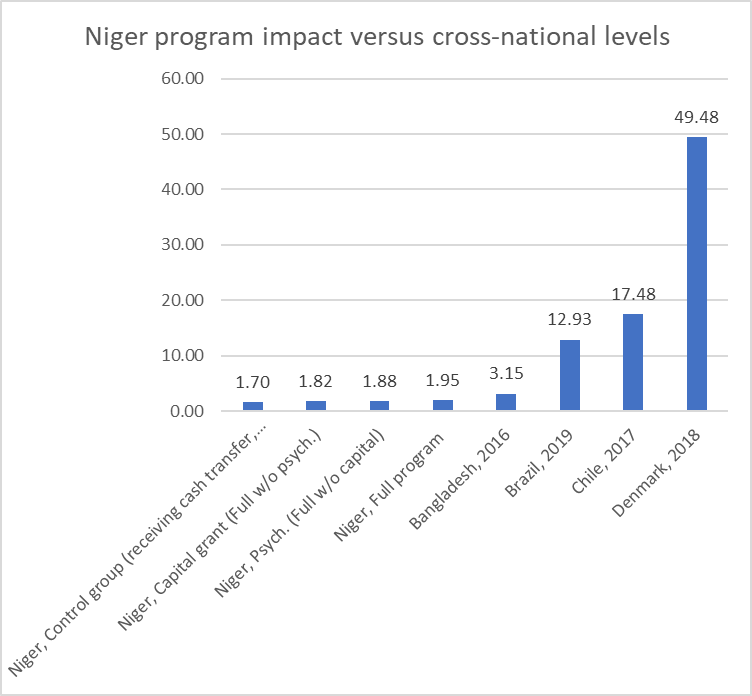
A really excellent academic paper often clarifies issues far beyond the particular point the paper makes. A recent paper in Nature magazine evaluates the impact of different components of anti-poverty programs. The paper shows that adding a “psycho-social” component to an anti-poverty program in Niger is enormously cost-effective, as it had similar impacts as adding a cash grant but was much less expensive. The paper, with 11 co-authors, is an exceptionally solid contribution.
And, what the paper indirectly illustrates so well is the difference between doing research about development and research about charity work. The development question is: “How can the people living in Niger come to have broad based prosperity and high levels of wellbeing?” The charity question is: “If some agency (perhaps of a government) is going to devote a modest amount of resources to targeted programs that attempt to mitigate the worst consequences of a country’s low level of development, what is the most cost-effective design of such programs?”
The paper is titled: “Tackling psychosocial and capital constraints to alleviate poverty” but does not start with the question: “What could lead to prosperity in Niger?” or even “What could lead to substantial reductions in poverty (at various poverty lines) in Niger?” Rather it starts with questions of program design: “How could a particular, already existing, targeted cash grant anti-poverty program in Niger be more (cost) effective at producing gains for its beneficiaries?” That is a great question but also a question that is a vanishingly small component of the first two questions.
Let me start with a graph I made from findings from the paper of the 18 month impact of different program designs (in addition to the cash grant received by the control group) on consumption per equivalent adult (Extended Data Table 1). This illustrates the basic finding of the paper which is that adding the psycho-social elements to the program alone (without a cash grant) raised household consumption from $1.70 a day per equivalent adult to $1.88 a day per equivalent adult (they also show impacts on a wide array of other indicators). Since, as they show in Extended Data Table 9, the psychosocial components were inexpensive this meant they had an astronomical benefit/cost ratio.
I am now going to show those exact results framed with three additional pieces of information.
(And these consumption numbers are not exactly comparable because, while all are PPP, they are not deflated to the same year and there are differences between “per equivalent adult” and per person.” But this as this is a blog, not a paper, and for the magnitude of what I am illustrating these differences are almost certainly de minimis).
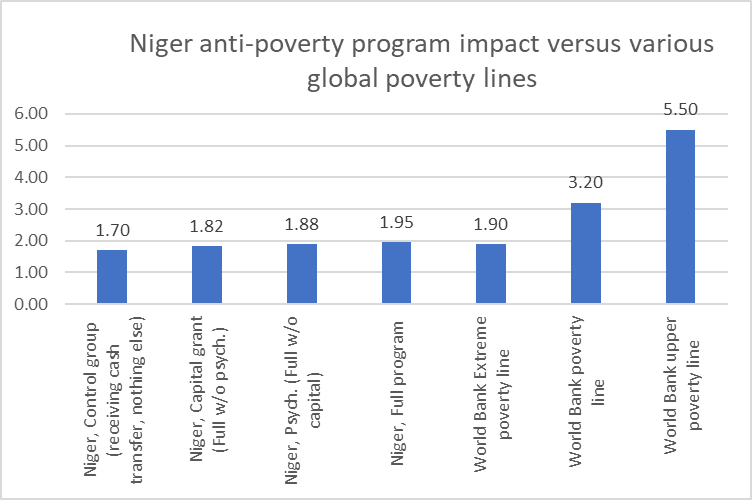
First, this program clearly raised the consumption of poor households in a poor country, but how much did the program reduce headcount poverty? Well, that completely depends on the poverty line that one uses. The World Bank, for instance, now reports three different poverty lines, which one could call “extreme poverty” ($1.90 per day per person), “poverty” ($3.20 per day per person) and, at a higher line, something called, perhaps, “global poverty” ($5.5 per day per person).
The program, by having a better design, raised the consumption of the beneficiaries by 25 cents per day, pushing the average of control group from below the extreme poverty line to just above the extreme poverty line ($1.90/day) for full treatment group. However the extreme poverty line is more or less a completely arbitrary number and many other poverty lines are as completely defensible as this poverty line (including poverty lines much higher than $5.50/day). At the $5.50 line the control group is $3.80 below the poverty line and an increase of 25 cents a day eliminates only 6.6 percent of the gap to be out of poverty.
Of course the obvious response is that, at Niger’s level of per capita income and hence available resources it is impossible to fund any program that could raise consumption by that much. But that is exactly my point. My point is that there is the question: “What could Niger do to reduce poverty over the medium to long run?” and then there is the question: “What can pragmatically done with the available resources with the best designed targeted anti-poverty programs?” The former question is far and away the most interesting and the answer to the latter question, with respect to any reasonable and humane poverty level is: “not much.”
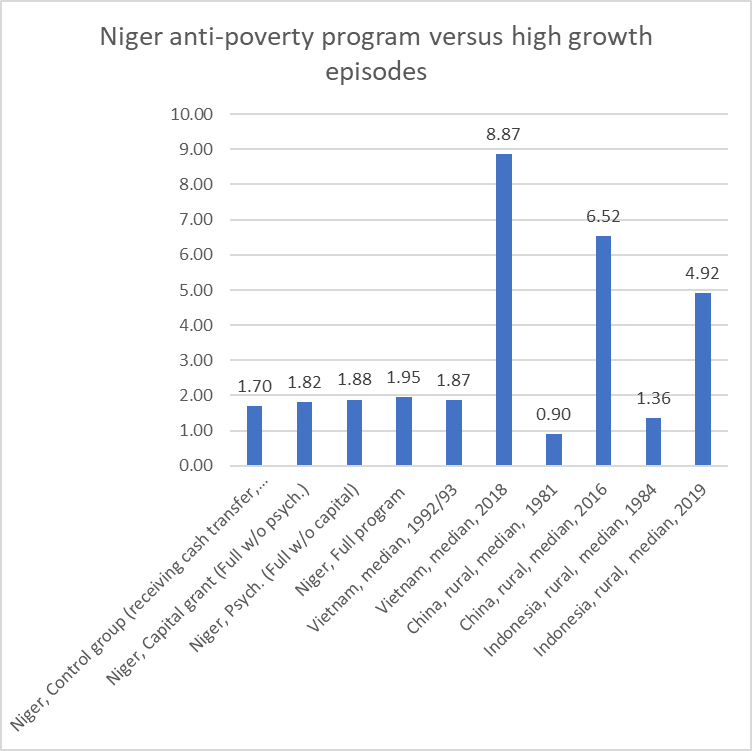
A different variant is to compare the gains in per person consumption of the “full program” treatment group to the gains for the median household from extended episodes of rapid growth. Again we see the terrific and cost-effective gain from $1.70/day to $1.90/day. In the 25 years from 1993 to 2018 the consumption of the median household in Vietnam went from about the level of those in the study in Niger, $1.87, in 1993 to $8.87 in 2018. This increase of $7/day is 28 times larger than the gain from the full program. Economic growth in Vietnam essentially eliminated extreme poverty, drastically reduced poverty, and even global poverty ($5.5/day) was well less than half the population in 2018.
The rural population of China went from having median consumption only about half that of the Niger study ($.90/day) in 1981 to $6.52 in 2016. Similar, though not as dramatic, gains were seen between 1984 and 2019 in rural Indonesia but still dwarf the programmatic impacts.
Again, I anticipate the response of “why not do both?” Of course, I am all for that. I am all for the funding of cost-effective targeted anti-poverty programs. But while it is optimal to do both, we development economists should keep in mind that sustained economic growth is empirically necessary and empirically sufficient for reducing poverty (at any poverty line) whereas targeted anti-poverty programs, while desirable, are neither necessary nor sufficient. Advocates of poverty programs say things like “growth is not enough” or that poverty programs are “equally important” as economic growth but these claims are just obviously false.
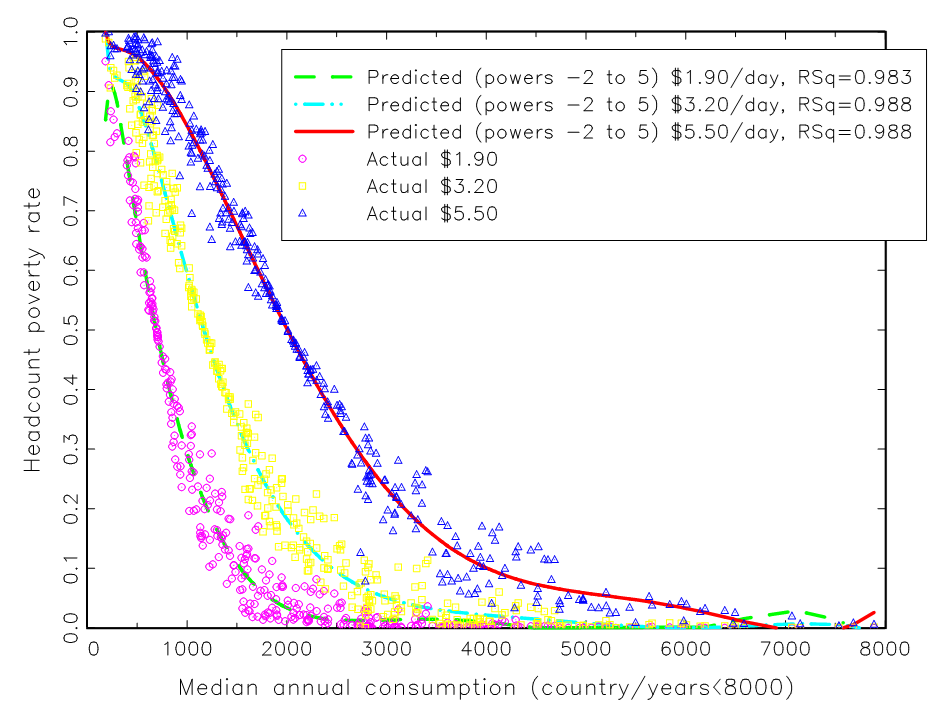
(This is well illustrated by the graph from Pritchett 2020 showing the very, very strong association of poverty headcount, at three poverty lines, and the median income/consumption of the country/year of the poverty estimate. At the “full program” consumption of $1.95/day the annual consumption would be $711 and countries with that level of median consumption all have $5.5/day poverty above 85 percent of the population.)
The third comparison is to cross-national differences in consumption of the median household. Development was always about the “developing” countries reaching the same levels as the “developed” and so one might ask, “how far along the spectrum of development does the program move households?” The additional 25 cents a day takes the targeted household about 17 percent of way to the median level in a poor country like Bangladesh, only about 2 percent of the way to the median for a country like Brazil and an inconsequentially small fraction of the way to the level of a typical (median) person in a rich country like Denmark. Even the best targeted programs are a just a tiny slice of development.
The paper shows that adding “psychosocial” elements–“life skills training” or “community sensitization on aspirations and social norms”–to anti-poverty programs might be cost-effective addition to anti-poverty programs and have a high rate of return. But that is not how, in fact, poverty has been substantially reduced in any country, ever. The massive reductions in poverty that we have seen both historically in the rich countries and more recently in the developing world has been through raising the productivity of the place so that individuals can use their resources to generate higher levels of income.
Moreover, it makes my very, very nervous the paper can and will be used (wrongly) to claim “since psychosocial interventions reduce poverty, it must be poverty was caused by a lack of psychosocial skills.” People in Niger are poor primarily because of the very limited choices they have not primarily because of the choices they make.
I am praising this paper. It is an excellent RCT impact evaluation that reveals interesting things about the design of targeted anti-poverty programs. But since it is such an excellent paper it reveals the deep and inherent limitations of this line of research. Better design of targeted anti-poverty programs is not an anti-poverty strategy, it is, at best, just one useful tactic.
Among the national governments–and populations–of the countries I have lived and worked in, the question about poverty and anti-poverty programs is just one question–and frankly, not their most important question. Their question to me is usually more of the type “How can my country come to have the levels of productivity, material prosperity, and wellbeing that countries like yours enjoy?” That, to my mind, is the development question.
In this piece (which is more than a blog and less than a paper) I support the claim that more rapid and sustained economic growth should be acknowledged as a (perhaps even “the”) key objective of “development.” All development actors should acknowledge this—governments, international agencies, bilateral agencies, development banks, development academics, (development) NGOs, philanthropists. Even if an organization or individual decides that promoting more rapid sustained economic growth isn’t their organization’s comparative advantage and/or priority and/or cup of tea, they still should acknowledge growth as an important and legitimate objective of development efforts.
An important element of my argument is separating whether economic growth should be a priority for “developed” or “rich” or “rich industrial” countries from the question of whether it should be a priority for poorer countries. The Organization for Economic Cooperation and Development (OECD) has a large project researching other policy objectives to supplant the (supposed) dominant position of economic growth. More strikingly, the Prime Minister of New Zealand, Jacinda Ardern has explicitly rejected GDP and economic growth as objectives for her government. As I make clear below, I take no issue with those positions in and about policy stances towards economic growth of developed countries for themselves. But preferences are not priorities and developed countries can recognize that further economic growth of income from its already high levels is not a priority for their country and yet, at the same time, acknowledge that economic growth is an (perhaps “the”) key objective for poorer countries and hence support development activities that promote more rapid and sustained economic growth.
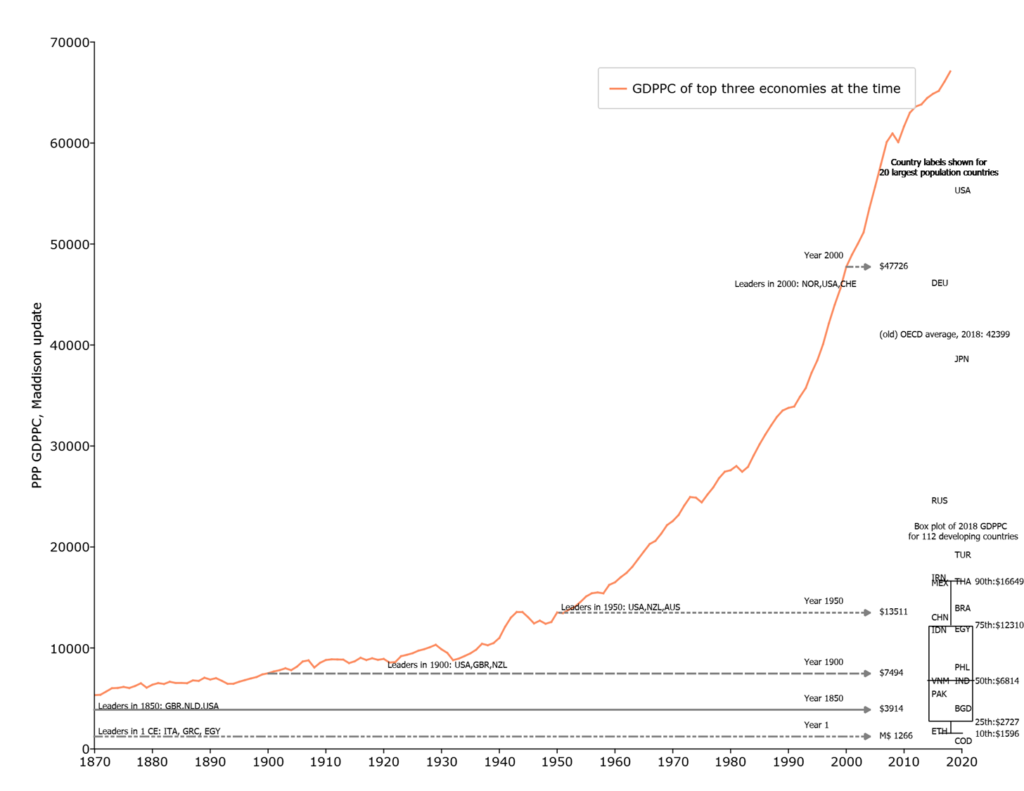
Graph One: The Hockey Stick with a Box Plot
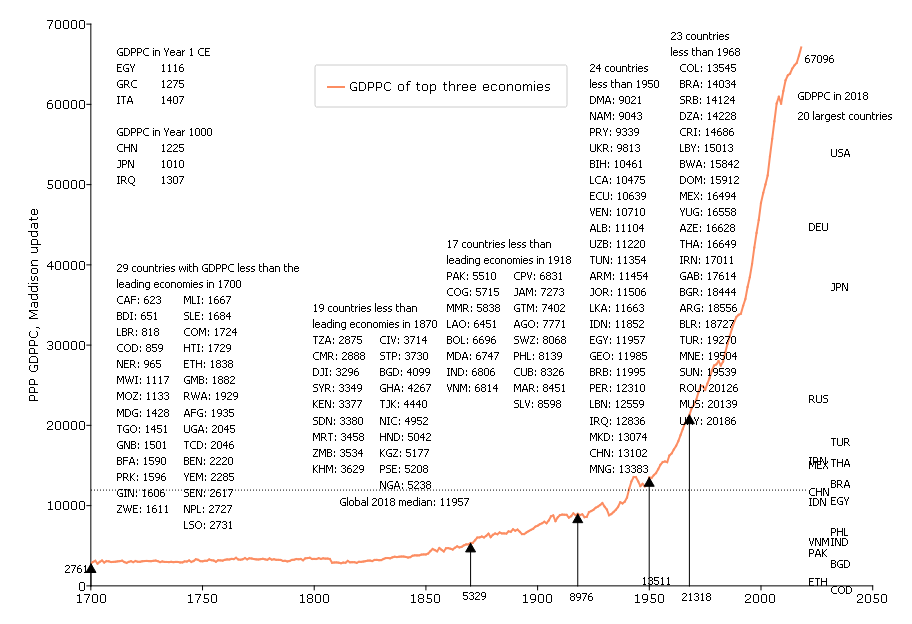
Figure 1 uses recently updated Angus Maddison-style estimates of GDP per capita from Bolt and van Zanden (2020) to compare the historical evolution of the GDPPC of the “leading” economies versus the GDPPC of the developing countries in 2019. GDPPC is in 2011 Purchasing Power Parity units which I call “M$” (for “Maddison-style PPP dollars”).
The orange line in the figure shows the historical trajectory of GDPPC of the highest three industrial countries (hence excluding the oil rich countries and a few small outliers (e.g. Luxemburg)). The level of the three leading economies in 1 CE (common era) (which were Italy, Greece, Egypt) is shown at M$1266. The average of the three leading economies in 1850 (which were Great Britain, Netherlands, USA) is shown at M$3914. This shows that the increase in the productivity frontier, the GDPPC of the leading countries, progressed very slowly throughout history as the level in 1850 was only about threefold higher than the level when Caesar Augustus ruled the Roman Empire, a compound growth rate of only .06 ppa (percent per annum).
Since sometime around 1850 “modern” sustained exponential growth of around 1.7 percent per annum (ppa) kicked in in the leading countries of the world and the graph shows the evolution of the three leading GDPPC countries in the world from 1870 to 2018 (which countries those were changed over time).
At the right edge of the graph I show the box-plot of the distribution of 2018 GDPPC for 112 developing countries—defined for this graph as those with GDPPC less than M$21,000. The box plot shows the 90th, 75th, 50th (median), 25th, and 10th percentiles of GDPPC.
I label the 2018 GDPPC only for the 20 largest population countries (because labeling all countries gets visually messy).
This somewhat unusual combination of a “time series” diagram and a “cross-section” diagram allows the visual comparison of (roughly) current GDPPC of developing countries to the level of GDPPC of the historically leading countries.
Three observations.
First, the typical poor country has a level of GDPPC that the leading countries had more than a century ago. The median developing country GDPPC is M$6814 (roughly the 2018 level of Vietnam and India) which is substantially below that of the leading countries in 1900.
Second, the poorest countries of the world (e.g. Ethiopia, Democratic Republic of Congo (COD), Niger) are at levels of GDPPC comparable—or lower—than those of Egypt during the Roman Empire 2000 years ago.
Third, three quarters of developing countries have a level of GDPPC lower than the leading countries in 1950, the 75th percentile (e.g. around China, Indonesia, Egypt) is M$12310. The nature of exponential growth is that the same growth rate produces larger and larger absolute increases so the leaders in the year 2000 were at M$47,00—which is M$33,000 ahead of where they were in 1950. Progress in absolute gains from 1 CE to 1900 was only about M$6200 so there has been five times from gain from 1950 to 2000 than from the time of Caesar to the Victorian era.
The main point of this graph is that it would be expected and natural for the currently high income countries to have very different priority of further economic growth than the currently poorer countries as their current level of GDPPC is so high relative to both their own history and other countries today. Three quick observations:
There was little to no discussion in the now leading countries that economic growth was not desirable and needed in 1900 but rather that economic growth was not a high priority this seemed to have emerged gradually. The American politician Robert F Kennedy gave a very famous speech in which he attacked GDP as a goal in 1968. In 1968 GDPPC was already M$23,691, well above any currently developing country and 3.5 times higher than the median developing country in 2018.
Even at the currently very high levels of GDPPC of M$40,000 the debate is whether growth of GDPPC should receive less weight or “not a priority” but no leading politician has proposed adopting a policy of zero economic growth.
No leading politician in any advanced country is suggesting that it would be desirable if GDPPC fell—even a tiny bit.In the massive financial crisis of 2007-2009 personal consumption expenditures fell from US$33,001 in 2008 to US$32,194 in 2009 and this was considered a political catastrophe and every available effort was made to reverse that decline.
Practically no one (or no one practical, which is often the same thing) is proposing reducing GDPP to the current levels of any of the developing poor countries. While New Zealand might not be enshrining GDPPC growth in its current priorities, neither is it suggesting a return to its 1950 level, where the now poor countries are.
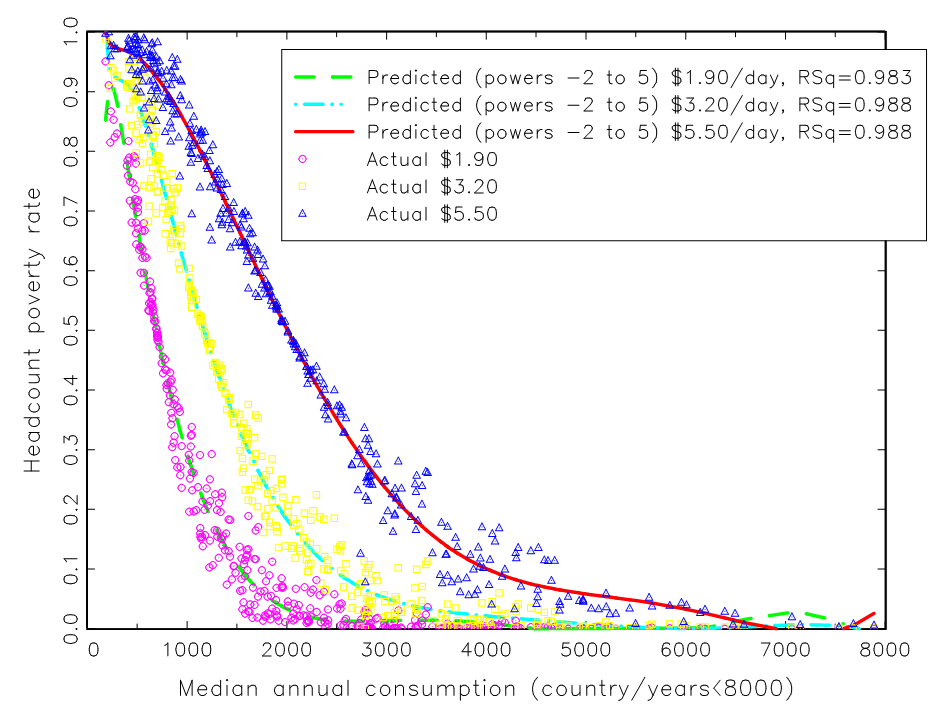
Graph Two: Median (typical) household income explains essentially all poverty differences across countries (in levels and over long episodes)
There is a relatively large literature about the relationship between “economic growth”—taken as the growth of GDP per capita—and standard Foster, Greer, Thorbecke (1984) measures of poverty. What the World Bank reports as the poverty rate (or number of people in poverty) is “headcount” poverty (FGT(α=0) for a given poverty line using data on household income or consumption (depending on what is available, most very poor countries do not (cannot? ) measure income reliably). This includes a set of papers by David Dollar and Aart Kraay (with others) (Dollar et al., 2016; Dollar et al., 2015; Dollar & Kraay, 2002)—and a very recent paper by Bromberg (2022).
The relationship between the headcount poverty rate and GDPPC combine (at least) three empirical issues:
How much of GDPPC is consumption expenditures
Whether the consumption expenditures measure in national accounts accords well and/or tracks with measured consumption expenditures in household surveys (for instance, in India, there has been a very large and persistent difference in the growth rate of PCE in that national accounts and the growth of average consumption expenditures in the household surveys used to measure poverty rates leading to very different views on poverty rates (e.g. Bhalla, Bhasin, and Virmani 2022).
National accounts PCE per person is a mean and hence changes in inequality at the upper end of the distribution can affect growth of the mean without changes in other measures of the central tendency of the distribution, like the median.
The graphs here use a different concept of “economic growth” which is the growth of the median of the distribution of consumption/income that the World Bank uses to compute poverty rates. So, rather that ask “how much of the variation in the poverty rate across countries and time is associated with variation in GDPPC across countries and time?” I ask, “How much of the variation in poverty rate across countries and over time is associated with variation in the level or growth over time of the consumption of the typical household (which is an alternative measure of the central tendency of the distribution)?
I use the raw data from the World Bank’s PovCalNet to create this graph.
I do the graph for the three poverty lines the World Bank routinely reports (P$1.9 /day,, P$ 3.2/day and P$5.5/day) where all are in purchasing power parity unite (the adjustment of which can lead to changes in measured poverty ).
In order to create relatively complete and timely reporting of poverty rates even though the raw household data collection is sporadic the World Bank “fills in” poverty rates. In my graph I only use the country/year poverty and median data that are near to the date of an actual survey.
I use only those country/year data based on consumption data (not income data, which may or may not fully reflect the post tax and transfer distribution).
The first figure shows the connection between the level of the headcount poverty rate and the median for 189 country/year observations. In order to allow the association to be as flexible as possible I use a functional form for median consumption with powers from -2 to +5, the connection between poverty rates and median is analytically non-linear (Bromberg 2022). The figure I truncated at P$8,000 as above that level poverty is essentially zero for all poverty lines.
The second figure examines changes over time. With a highly non-linear functional form one cannot just run a “changes on changes” regression. Rather the graph calculates the predicted poverty rate at the beginning and end of the data for each country using the level estimates and then shows the association between the actual change in poverty rate and the change in the predicted poverty rate on the assumption of a stable non-linear relationship over time.
Source: Pritchett 2020, Figures 3 and 4.
The finding that emerges clearly is that essentially all of the variation across countries/over time in the reported World Bank headcount poverty rates is due to variations in the income of the typical (median) household in the country/year. An R-Squared of .988 is practically unheard of as measurement error in either the left hand or right hand side variables lowers the R2. (For instance, in Filmer and Pritchett 1999 we show that if one uses different years of the same data source, the Demographic and Health Survey (DHS) to measure child mortality of the same cohort of women recall error produces an upper bound on the R2 of the cohort child mortality rates of only .95.)
Some might object that this result is “baked in” as the estimated poverty rate is just the partial integral of up to the poverty line of the same distribution used to compute the median so the difference cannot be that big. But since I am using only consumption data the data is, in principle, a post tax and transfer measure so that any programs that raised the consumption of those below the poverty relative to the median would in fact cause a deviation of poverty from the pre-tax and transfer distribution of income.
The impact of targeting anti-poverty programs therefore should be reflected in this graph and hence the graph of levels suggests that at the very most 1.2 percent of the cross national variation in poverty rates could be due to the effects of programs that affected “the poor” without affecting the median.
This raises two points that help produce this very strong result.
First, in many cases the poverty line is above the median HH income and hence the poverty rate is higher than 50 percent. (one can see in the graph that the association gets very right when the headcount poverty rate is near .5 for each poverty line).
Of course, in poverty measures that reflect the “intensity” over poverty, such as the FGT(α=1) “poverty gap” or FGT(α=2) “squared gap” measures, could be affected by anti-poverty programs. But these are rarely reported or used (more on that below).
Second, the results suggest that the magnitude, efficiency, and efficacy of anti-poverty programs is a very, very small part of the level of change in poverty over long episodes. My argument is that, on reflection, this should strike us all engaged in development as quite “intuitive” on each aspect.
The magnitude of targeted anti-poverty programs in poor countries is going to be limited by the ability to mobilize tax revenues (and poor countries consistently have lower tax/GDP ratios Burgess and Stern 1993, Besley and Persson 2013, Jensen (2019)) and by the many competing demands for those scarce fiscal resources (for external security and law and order, for infrastructure (roads, power, water, sanitation), for education, for health, for regulation, for administration, etc.).
The fiscal efficiency of a targeted anti-poverty program can be measured as the ratio of the dollars in budget allocated that reach program the activities and benefiting targeted individuals. One well known fact is that generally measured “state capability” is lower in poorer countries so one can easily doubt that either (a) identifying the poor (which is administratively demanding even in a static sense, and static targeting is not very effective at reaching the poor as poverty status of households changes over time (Jalan and Ravallion 1998, Sumarto, Suryahadi and Pritchett 2000) and dynamic targeting is very demanding) and then (b) ensuring against leakage (of at least three types: (i) corruption to rent seeking government (political or administrative) offices, (ii) excess costs of administration, and (iii) mis-targeting of benefits) is going to be a strong suit of a poor country government.
The efficacy can be measured as the magnitude of the (sustained?) gain to the household from the activities. It has been a major research agenda to investigate whether common anti-poverty activities like micro-credit or business training are actually effective. While some activities have been demonstrated to be effective in some (but not all) contexts when implemented by NGOs (e.g. “graduation” style programs Banerjee et al 2015), they are quite complex in design (and that complexity appears to be essential to success) and implementation by governments is by no means assured.
The figures just show that in the data available so far, if “economic growth” is taken to mean the growth of the central tendency (median) of the distribution of consumption has been a very strong empirically necessary and empirically sufficient for headcount poverty reduction.
This is not to say that governments (or NGOs or philanthropists) cannot reduce poverty through greater fiscal allocations, greater efficiency or greater efficacy nor that research (including using rigorous methods) might not contribute to that. But this is likely to be a very, very, small part of the overall dynamics of poverty.
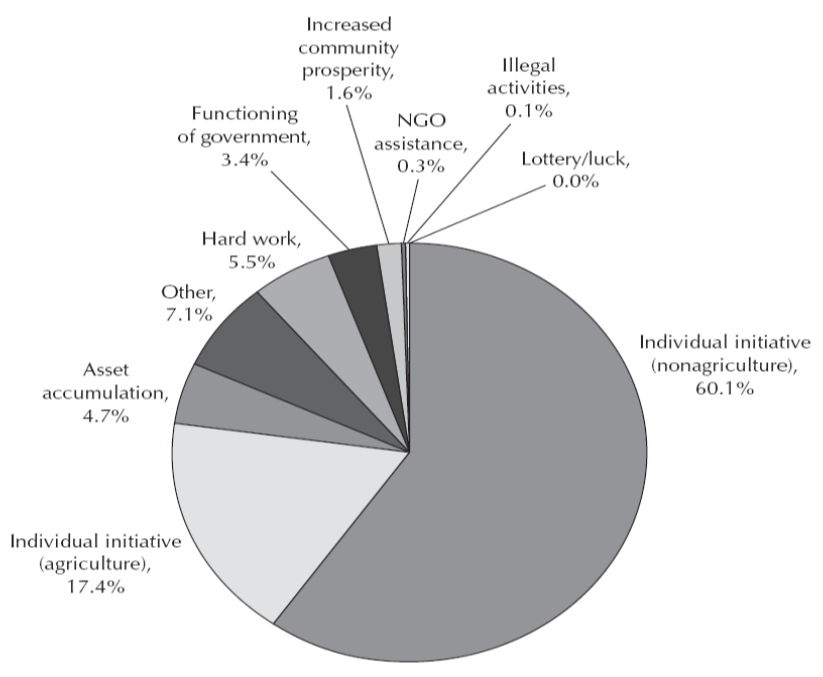
One additional figure, that I will not count as one of the “five” is, in some sense, the micro, qualitative counterpart of the macro figure. In the major study Moving out of poverty (vol 2); Success from the Bottom Up a “ladder of life” community focus group was used to identify those in the village who had, in the last 10 years, moved out of poverty. These households, identified by their neighbors as having moved out of poverty. were then interviewed about their own narrative of how they moved out of poverty. A figure from this shows the distribution of the responses among the almost 4,000 interviewees. In their own narratives their undertaking a new initiative (either outside of agriculture (60.1%) or in agriculture (17.4%) or hard work (5.5%) or asset accumulation (4.7%) or increased community prosperity (1.6%) accounted for nearly all the moves out of poverty.
Source: Narayan, Pritchett and Kapoor (2009)
Graph 3: National Development Delivers
One of the elements of a push back (mostly in currently rich countries) against economic growth as an key policy objective is that it is not tightly connected to human wellbeing. For instance, an organization called the Social Progress Initiative has proposed the development efforts should be guided by non-economic measures of progress and have created for that purpose a Social Progress Index (SPI).
We dream of a world in which people come first. A world where families are safe, healthy and free. Economic development is important, but strong economies alone do not guarantee strong societies. If people lack the most basic human necessities, the building blocks to improve their quality of life, a healthy environment and the opportunity to reach their full potential, a society is failing no matter what the economic numbers say. The Social Progress Index is a new way to define the success of our societies. It is a comprehensive measure of real quality of life, independent of economic indicators.
The SPI is an aggregate of three components, each of which is itself has four elements:
Basic Human Needsis the average of (i) Nutrition and Basic Medical Care, (ii) Water and Sanitation, (iii) Shelter, and (iv) Personal Safety
Foundations of Wellbeingis the average of (i) Access to Knowledge, (ii) Access to Information and Communications, (ii) Health and Wellness, and (iv) Environmental Quality
Opportunity is the average of: (i) Personal Rights, (ii) Personal Freedom of Choice, (iii) Inclusiveness, and (iv) Access of Advanced Education.
My argument is that development efforts have routinely be predicated on the idea that “development” is a four-fold transformation of economy, administration capability, polity, and society at the country level and that, if successful, higher levels of national development will lead to higher levels of human well-being.
This leads to an empirical question. Suppose I regress the SPI across countries on three measures of national development: national development, state capability, and democracy (as a proxy for “polity”), how much of the variation in SPI will be captured by just these three measures of national development? Pritchett (2022) shows that the answer is that the R-squared of regressing SPI on these three elements of national development is .9 (since the R-squared is the square of the correlation coefficient this implies the correlation of actual SPI and a national development index constructed using the regression weights is .95).
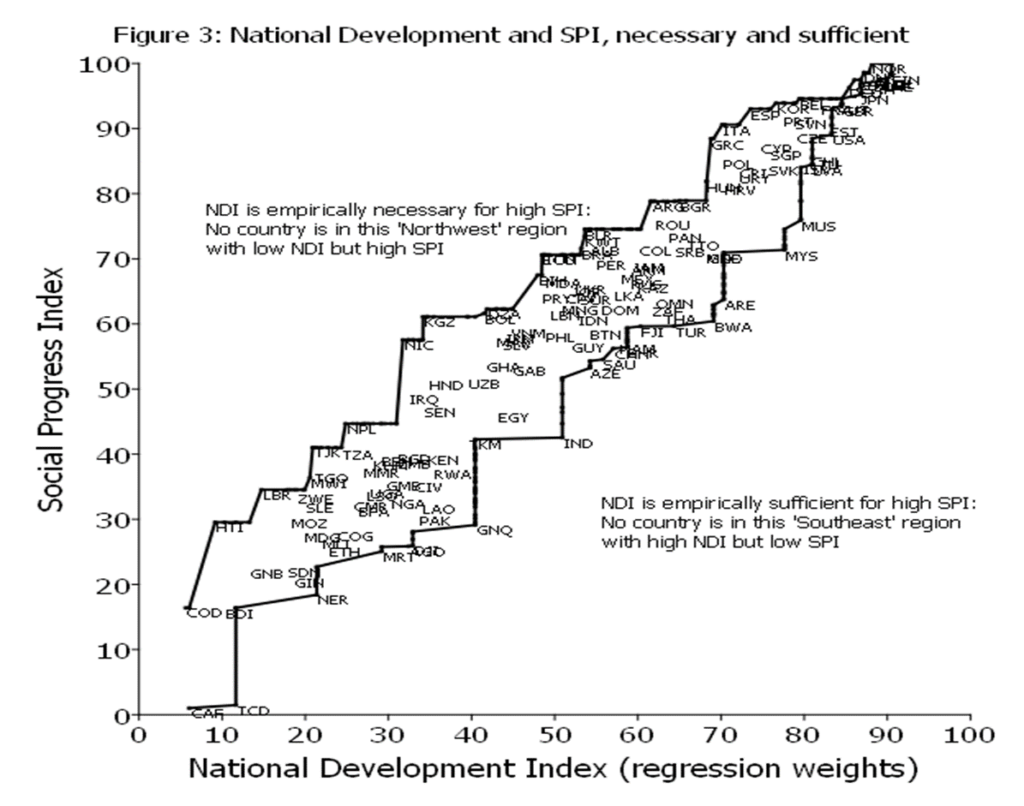
I invented a graph to illustrate the connection between the SPI and the NDI (national development index, which is the regression weight index of the three elements of national development), which is an “envelop” graph because the envelop shape completely encloses all of the country experiences.
The lower bound of the envelop is the worst SPI is for any country with that level of NDI or higher. For instance, India (IND) has the lowest SPI of any country with its level of NDI or higher, there are countries with higher SPI at their level of NDI but only countries with lower NDI have lower SPI.
The upper bound of the envelop is the country with the highest SPI for any country with its level of NDI or lower. For instance, Nepal (NPL) has a high SPI with a low NDI. There are countries at higher SPI, but only those with higher NDI.
The attractive feature of an enveloping graph is that the white space is meaningful as it illustrates the combinations of SPI and NDI that have not happened. This illustrates how empirically necessary and empirically sufficient NDI is for achieving human wellbeing (as proxied by SPI).
NDI is strongly empirically necessary for high levels of human wellbeing. The empty “northwest” of the graph shows that no country has high SPI with low NDI. For instance, Argentina (ARG) has a level of SPI around 80 and is on the upper range of the envelope. Argentin’’s NDI is around 70 and no country has achieved a SPI above 80 with NDI below 70.
NDI is also strongly empirically sufficient for high levels of human wellbeing. The empty “southeast” of the graph shows that countries do not have high GDPPC, strong state capability and democracy and still have low levels of human wellbeing. Malaysia (MYS) for instance, does have SPI much lower than other countries at similar NDI (such as Spain or Korea) but its SPI is still higher than the SPI for any country with NDI of 60 or less.
Even with the measures of human wellbeing proposed by advocates who are working against the supposed current “over emphasis” on growth, national development delivers. It is just not the case that countries get to high levels of overall, omnibus, wellbeing without national development nor do countries achieve high levels of national development and not have high levels of human wellbeing.
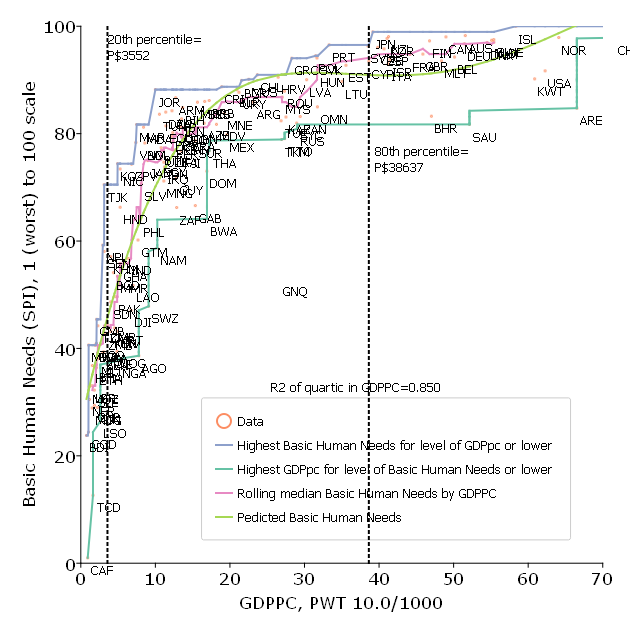
Graph 4: Basics and GDPPC
The Social Progress Index is one possible aggregate index of human wellbeing, but one might legitimately be concerned about a narrower indicator of “the basics”—elements of human wellbeing that are prioritized by people with low incomes.
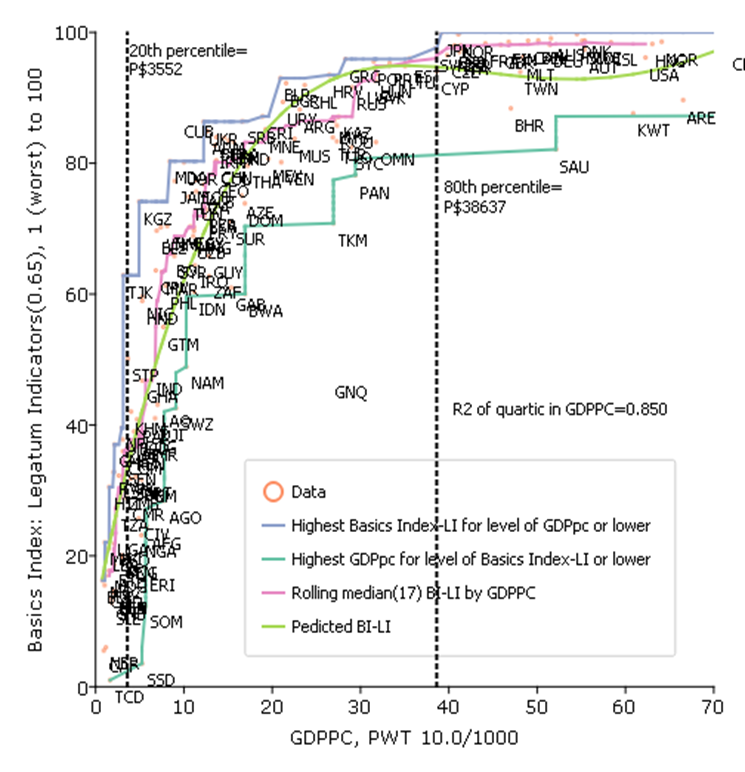
In Pritchett and Lewis (2022) we examine a wide variety of ways to construct a country level measure of the basics of human wellbeing that covers a variety of dimensions (health, education, water and sanitation, infrastructure and housing conditions, poverty, natural environment). We show that no matter how one builds an index of basics the relationship between BHWB and GDPPC is roughly like this figure, for which the indicator of “basics” is built from a set of 82 potential wellbeing indicators from the Legatum Prosperity Index, each of which is scaled to that the worst country is 1 and the highest country outcome is 100 (so this puts all indicators on a common scale but preserves cardinality of each indicator).
There are two important features of this graph.
One, the relationship is strongly non-linear and the BHWN rise very steeply with increases in GDPPC and then tapers off and then above a high level (say, the 80th percentile of countries at GDPPC of (roughly) P$40,000 it is essentially flat. (This non-linear relationship is shown both with an OLS regression with a quartic in GDPPC but also in a non-parametric, robust statistic of the rolling median).
Second, the relationship is “tight” in the sense that the association is very strong.
The same “envelopment” curve approach as in the previous grapth shows that not just national development but GDPPC alone is strongly sufficient for BHWB.
The one country not included in the envelopment is Equatorial Guinea (GNQ) which is the exception that proves the rule, in that GNQ has high GDPPC because of oil production but given than GNQ had a horrific government (since its independence from Spain in 1968 it has had two dictators (uncle and nephew) this high level of GDPPC has not translated into benefits for the population.
GDPPC is also “empirically necessary” for high levels of BHWB. Every country in the bottom 20 percent of GDPPC has very low levels of basics. At middling levels of GDPPC there is more variation, but it is still the case that no country with low GDPPC achieves high level of BHWB characteristic of all of the OECD countries. For instance Cuba is often cited as a country that achieves high levels of wellbeing at low levels of income, and indeed it does, but it is still substantially below the level of every OECD country.
The very important implication of this graph is that “preferences don’t determine priorities.” It would be perfectly natural for a country at the median level of GDPPC to be highly focused on rapid and sustained economic growth in order to provide the material basis for achieving high levels of the basics of human wellbeing.
And, by the same token, countries at very high levels of GDPPC, like say, New Zealand, might decide that there are other higher priorities for wellbeing that economic growth and that they already have the high levels of economic productivity and material conditions to solve their problems.
But, what would be a massive mistake would be for people in New Zealand (or any other high income country) to conclude that since their priority was not on economic growth that other countries, in radically different material conditions and radically different levels of the basics, should not prioritize economic growth.
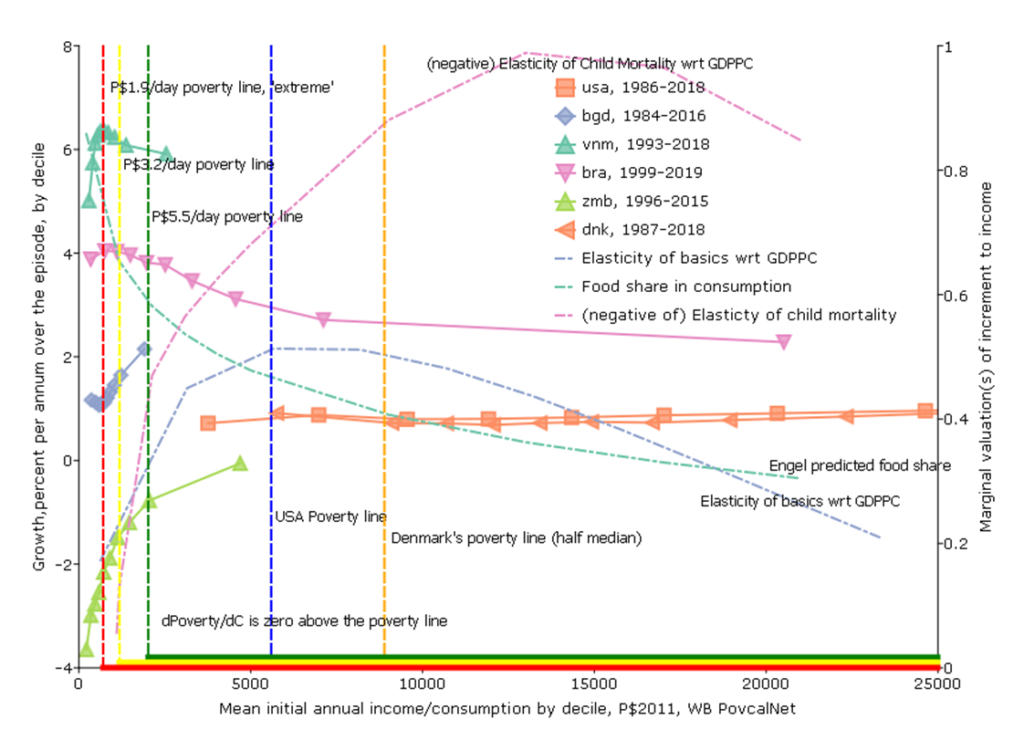
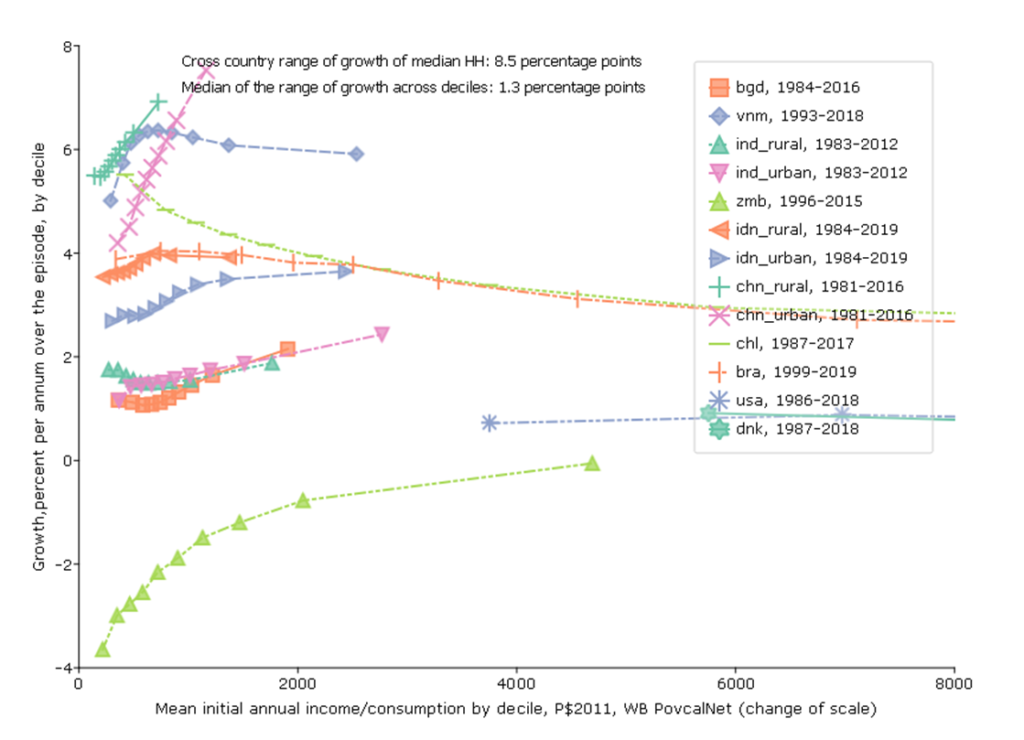
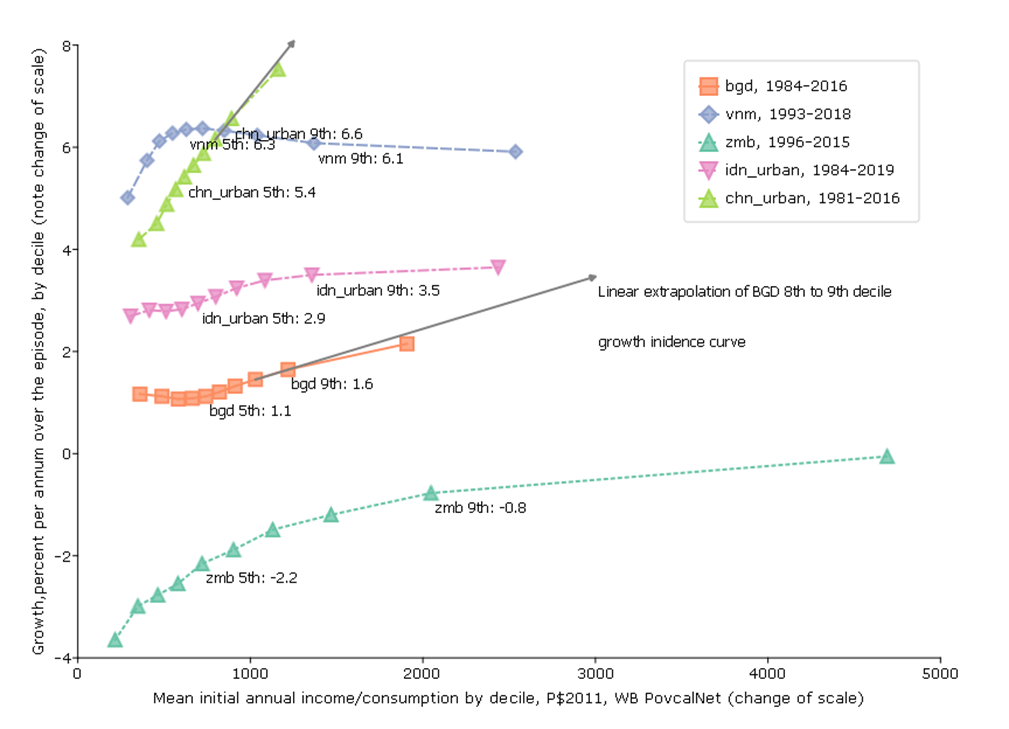
Graph 5: Growth Incidence (with five variants)
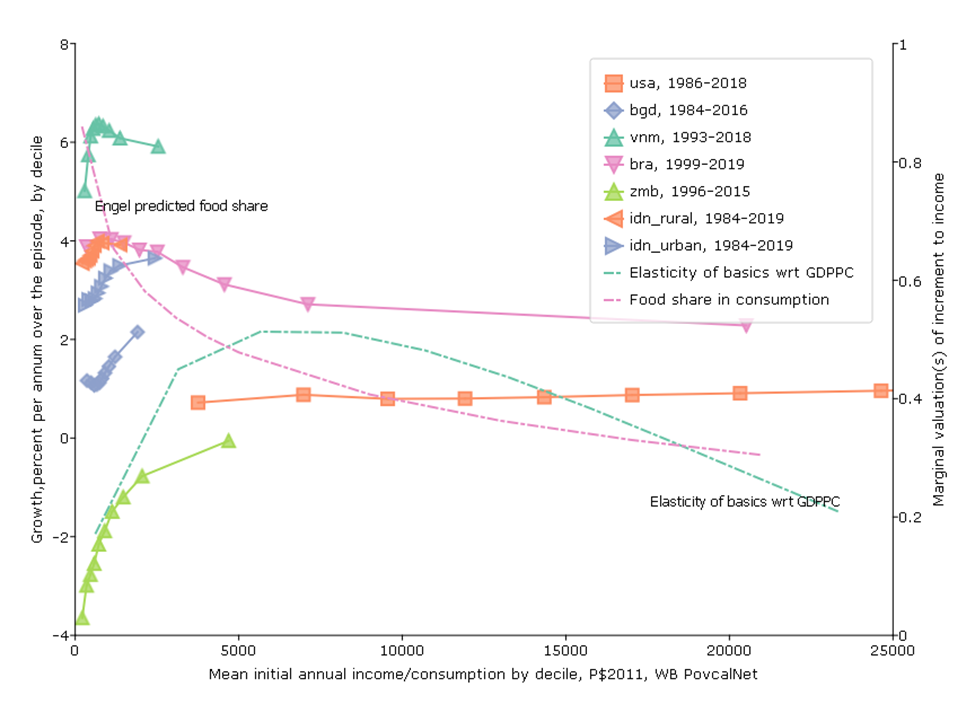
So far I have not used any of the very popular adjectival modifiers often appended to growth that characterize both the level of growth and its distribution–like “inclusive” or “pro-poor.” The last graph (which will need five variants just to convey the richness of what it can convey) addresses simultaneously: (i) the pace of growth, (ii) the level of income from which growth begins, (iii) the “growth incidence” which is the pace of growth for each of the deciles of income/consumption and (iv) the normative valuation of incremental growth across levels of income.
For this figure I again use the World Bank PovCalNet data and I use the longest possible data span (with survey based estimates, not extrapolated) for each country. I am not showing all possible countries, just countries selected to illustrate analytic features.
The horizontal axis is the level of income/consumption at the beginning of the episode for each country.
Then, for each country I show (left vertical axis) a standard “growth incidence” curve which is the percentage rate of growth of income/consumption (again, nearly always consumption for poor countries, nearly always income for middle income and rich countries) for each decile.
On the right axis I show various indicators that are relevant to the normative valuation of the growth of income at any given level of income. In the “basic” figure I show (i) the Engel curve that shows the predicted level of share of food in total consumption at each level of income and (ii) from the regressions of basics on GDPPC shown in the graph above (Pritchett and Lewis 2022) I show the elasticity of BHWB wrt GDPPC at each level.
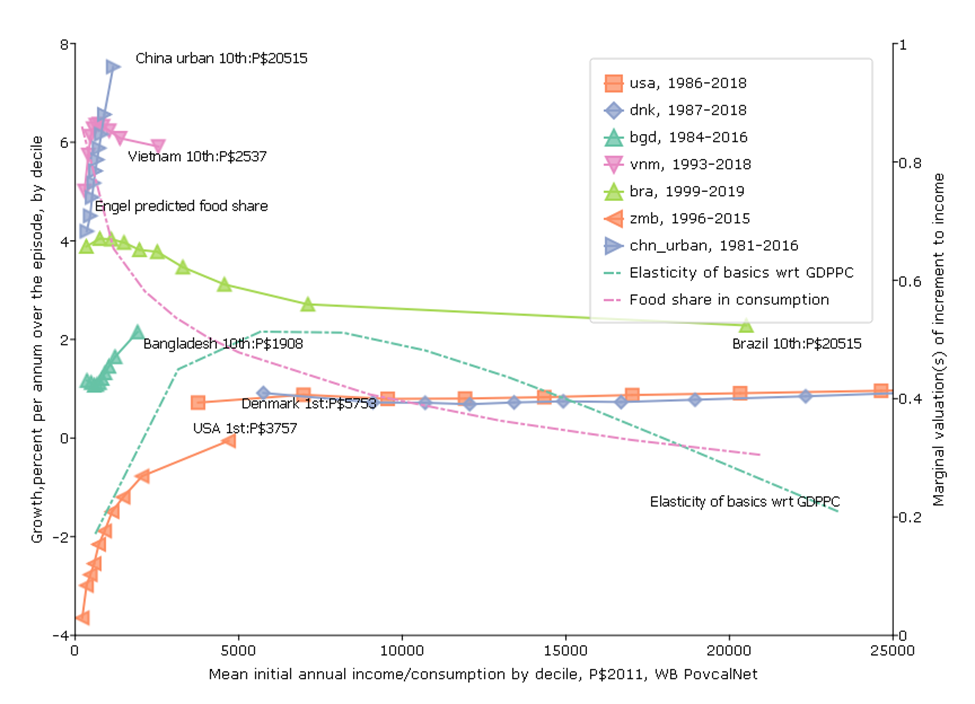
Fifth Figure, Variant 1: The rich of the poor are poorer than the poor of the rich
One common justification for reducing the priority to economic growth is that it just benefits “the rich” and “the rich get richer and the poor get poorer.”
This can be misleading and confusing as often people saying things like this are not clear on whether they are using the word “the rich” in a consistent way. Often people characterize “the rich” in relative terms to their own country and not in a consistent way comparing people across countries.
This confusion leads people who are “progressive” easily end up in a situation in which they are very much in favor of raising the income/consumption of one group (“the poor” of rich countries) but seem reluctant to support increases in income/consumption of people who are, in absolute terms, much poorer.
For instance, the average income (and this is income, not consumption) of the lowest decile in Denmark in 1987 was P$5753. Among the global policy crowd European countries like Denmark are often roundly praised for the variety of programs that raise the consumption of “the poor” in Denmark so that their post-tax and transfer consumption can be much higher than their pre-tax and transfer income.
But the average income of the richest decile in Bangladesh in 1984 was P$1908. And since these “purchasing power parity” comparisons they are adjusted for the fact it is cheaper to live in poor countries so this is at least meant to compare people’s purchasing power directly in absolute terms. So “the rich” of a poor country like Bangladesh are a factor of 3 poorer that the income of the poor of a rich country.
Many people are skeptical about this fact and believe that the PPP really compare standards of living (often with no good reason). But Pritchett and Spivack (2013) use data on the food share in consumption—which therefore involve no use of exchange rate comparisons of any kind—and the Engel curve to show that the differences in food share between “the rich of the poor” and the “poor of the rich” is consistent with the factor multiple differences in real consumption that PPP data show.
This “rich of the poorer are poorer than poor of the rich” is (of course) not true of upper-middle income countries with high inequality, like Brazil. The average income (and it is income, not consumption) of the top decile in Brazil is P$20, 515, which is will above the median of the USA or Denmark.
And one can also distinguish between the rich and the global hyper-rich like billionaires, which is an entirely different issue (as we discuss below).
Fifth Figure, Variant 2: Low bar poverty lines are economically indefensible (and morally obscene)
A second major objection to economic growth is to argue that the marginal normative valuation of additional consumption declines very rapidly to a very low level and hence growth may not be that important for a normative social objective function.
This normative under-valuation of income gains reaches truly surreal levels with “low bar” global poverty lines. The main feature that distinguishes the mainstream FGT(α) poverty measures from any other social welfare function (like, say, an Atkinson-inequality adjusted income measure) is not that “poverty puts more weight on the wellbeing of poorer HHs”—as all inequality averse measures do that—but that poverty measures put exactly zero weight on income above the chosen poverty line. For example, with the “dollar a day” poverty line (now P$1.9/day with inflation) if someone’s income increases from P$1.95 to P$2.00 this would have exactly zero impact on any standard (FGT) poverty measure using the P$1.90 poverty line.
This means that a standard normative welfare function and poverty as an objective only (roughly) coincide if one is willing to accept that the marginal valuation of consumption gains above the poverty line being used is (reasonably) well approximated by zero.
That view for the standard poverty lines used by the World Bank is, I would argue, complete madness, for four reasons.
First, there is no line. The opening of Alfred Marshall’s Principles of Economics was Natura non facit saltus (“nature does not jump” in Latin). The classification of something “above” or “below” some more or less arbitrarily drawn line through the income/consumption should not create the issue that things are qualitatively different below and above that line. If one examines wellbeing outcomes—health, education, malnutrition, access to water, etc.—there is often a reasonably strong connection between those “goods” and HH income. But I have never, ever, seen any empirically demonstrated discrete jump or “phase transition” around a specified line (or even a close approximation to it).
Second, even if there were a line above which it would be a reasonable approximation to treat consumption gains as having ‘near’ zero value it is nowhere near the World Bank poverty lines.
While there is no way to say what “marginal utility of income” is and how exactly it evolves with income the figure shows three pieces of empirical evidence.
One, I estimate an Engel curve relating food share in consumption to PPP consumption expenditures (and, as Pritchett and Spivack (2013) show the actual Engel curve parameters are remarkably similar over time and samples and method so the details don’t really matter). At the P$1.9 per day poverty line the predicted food share is around 80 percent. The marginal propensity to spend is less than the average (as it is declining) but there is no way one can argue that additional income has “about” zero impact on wellbeing when HHs are still spending 50 percent or more of the incremental income on food.
Two, the graph above showed that the slope of the relationship between basics and GDPPC was highly non-linear and that it was very steep at low levels of income. However, the more common measure of responsiveness is the elasticity (which is the percentage change of basics over the percentage change in GDPPC) and when one computes the elasticity of BHWB wrt to GDPPC it emerges that this slope actually starts out low and then increases as GDPPC increases up to a point and then starts to decline to much lower levels at high levels of GDPPC.
The striking thing is that at the highest of the WB reported poverty lines, of P$5.5/day, which is consumption per year of only P$5.5/day*365days/year=P$2007/year (and then adjusting the elasticity curve so that elasticity is predicted consumption not GDPPC) the elasticity or responsiveness of basics to increases is not only “near zero” and not only is it not decreasing, but rather it is still rapidly increasing. So countries with growth at the levels of the poverty lines are seeing basics of wellbeing (health, education, water and sanitation, etc.) improve at an increasing rate. To assert that zero is good approximation to the benefits of income about that level is well approximated by zero (as poverty as an objective demands) is surreal.
Three, I ran a regression of the standard World Bank Under Five Child Mortality data on a flexible functional form in GDPPC in part to illustrate that the shape of the elasticity is not an artefact of scaling or building an index. The same feature about the elasticity emerges as the responsiveness (elasticity) of child mortality to increases in GDPPC first increases (up to a quite high level) and then decreases (but is still very high even at the US 80th percentile). Again, I just don’t see how one can adopt “poverty” as the “objective” of development at such low poverty lines and then hence discount how much improvements in GDPPC contribute to improving wellbeing.
I am not making any of: (i) “materialist” case that money/income/consumption is the only goal (all of my arguments bring in other dimensions of human wellbeing, like child mortality or the natural environment), (ii) the case against declining marginal utility of income, (iii) the case that, at some level of GDPPC the attention should shift from prioritizing growth to other objectives.
But I am making the case that for a global poverty line something much more like Denmark’s poverty line of around P$25/day makes much more sense than a poverty line at less than 1/10th that value.
I am increasingly of the view that the implicit acceptance (or at least complicit toleration) of the “low bar” poverty lines that implied zero valuation of income gains above a ridiculously low threshold is the root of all evil in development. And I don’t mean “evil” in some vague metaphorical sense, I think the “golden rule” implies should only accept conditions for others we would accept for ourselves and no person advocating a “dollar a day” poverty line would ever accept that their own personal valuation of income gains above that threshold was zero. Low-bar lines do not pass a simple ethical test (and the philosopher Derek Parfit (2011) argues that something very much like the Golden Rule emerges from a variety of different ethical approaches).
Fifth Figure, Variant 3: Would you rather have a purple unicorn or a brown horse?
The third variant of the graph is to examine that growth incidence curves themselves considering both their slope/shape and their location. A key question is that if we have concern mainly for the growth of the lowest deciles is that primarily driven or determined by whether growth is “inclusive” or not (the shape/slope) of the growth incidence curve or by the average pace of growth for the economy at large (say, the average growth or growth of the median)?
For pretty much overall normative evaluation one (you, me) would rather have more rather than less “inclusive” growth (any sort of declining marginal utility gives that result).
But there is also the question would one (where “one” is you or me)—even if your only objective was growth of the poor rather have “inclusive slow growth” versus “pro-rich fast growth”?
For instance, this data suggests that over the period 1984-2016 the consumption of the poorest decile in Bangladesh grew at 1.1 ppa and the consumption of the rich grew at 2.1 ppa, a difference between rich and poor of only 1 ppa so, while growth was not “pro-poor”, the growth incidence curve was not very steep.
In contrast, growth of the poorest in urban China 1981 to 2018 was 4.2 ppa but the growth of the richest decile was 7.5 percent, higher by 3.2 ppa. This was “pro-rich” growth but but in absolute terms, the consumption of the lowest decile grew massively.
The consumption of the lowest decile went from P$360 to P$525 in Bangladesh 1984-2016, while over a much period of 1981 to 2016 the consumption of the lowest decile in urban China went from P$353 to P$1489—more than quadrupling.
This graph doesn’t “prove” the point or even fully illustrate it, but empirical analysis shows that the correlation between the growth of the poorest (1st decile) and the average growth in the country is very high (Dollar and Kraay 2002) and hence even though poverty rates are responsive to changes in inequality it is still the case that most of the variation in poverty reduction is due to differences in country average growth rates (Bromberg 2022) . This itself is just a consequence of the fact that (a) the cross-national and time series variation in growth rates is very high and (b) the cross-national and time series differences in measures of inequality (like the Gini coefficient) are very stable.
This point is important as a great deal of discussion in development circles is about the adjectives that modify “growth”—the goal is never stated as “rapid, sustained, growth” but as “inclusive sustainable growth.”
One might prefer a purple unicorn to a green unicorn but their ontological status is the same and neither can pull your cart as well as a brown horse.
Fifth Figure, Variant 4: There are episodes like “Equatorial Guinea”—but they are very rare—income growth and wealth growth are not the same dynamic
There have been two phenomena, mainly in the USA, that have sucked up the air in the economic growth room.
One, is that the growth incidence curve in the USA has been highly tilted with the top percentiles capturing a large fraction of the benefits of growth.
Two, Thomas Piketty (and a few others) have been remarkably successful in shifting attention from the distribution of flows (income, consumption) to stocks (wealth) and, while doing so ignoring the single most important asset for most people, huma capital, in favor of financial wealth. This has been associated with attention to the rise in the number of the globally hyper-rich (e.g. numbers of billionaires), which is again about a stock of financial wealth, not the flow of income/consumption.
This has supported a push-back against economic growth (without adjectives) as a goal with the notion that the “hyper-rich” are capturing disproportionately large parts of the economic gains. Of course starting from any given level of income inequality even if inequality is unchanged the rich already control a larger share of income and hence they will, even at “neutral” growth incidence in percent rate of growth capture the same share of the gains as of the levels. For instance, in the data in the figures the top decile in Bangladesh had 22 percent of the consumption in 1984 and hence even if the income distribution did not get more unequal they would have had 22 percent of the gains (to keep their share constant).
We cannot isolate the upper deciles precisely with the existing data by deciles, but we can do two calculations to show that the “hyper-rich” are not capturing all (or nearly all or even a large share) of the gains.
We take advantage of the fact that if the far right tail is included at all, it is in the average of the top decile—but does not affect at all the average of the deciles below. I show the average rate of growth of the average income 9th decile, which is truncated both below and above. This growth is robustly quite high. Two points.
First, just to illustrate why this calculation is relevant. Imagine there was an economy of 100 people and their initial income was log-normally distributed and then income stayed the same for 999 of them and only the income of the top person doubled. Then there would be substantial growth in the average income even though only one person’s income changed. But if we did the percent change in income by decile growth would be zero for all deciles but the top, so the growth incidence curve would be a flat line at zero and then a rotated “L” shape with only the top decile (where the top individuals are) having positive growth.
Second, that said, I am not denying that there might be concentration of wealth and power in very few hands, but only that this wealth dynamic is not what is driving the overall growth results.
Pritchett, L., & Spivack, M. (2013). Estimating Income/Expenditure Differences Across Populations: New Fun with Old Engel’s Law. Center for Global Development Working Paper, 339. https://doi.org/http://dx.doi.org/10.2139/ssrn.2364649
There is a constant steady stream of opinions that economic growth, and in particular, GDP per capita, is overrated and that it should be downplayed as a policy objective, mostly from people in the rich countries of the world (the OECD). My main point in the attached new (draft) paper is that priorities depend not just on what you want, but how much of what you want you already have. What makes the rich countries rich is that they currently have very high levels of GDPPC, and, given that they have a lot, they might, at the margin, want to value other things they also want they have less of.
But it is a huge, huge, mistake to think that priorities are just preferences and countries with low GDPPC, even if they want exactly what countries and people in the OECD want as preferences, might have a very strong priority for more economic growth as they have so little now.
There are two key graphs. One, from a previous paper of mine, is just a graph built on the (updated) Maddison-style estimates of long run GDPPC (Bolt and Van Zanden 2020). This shows the evolution of the GDPPC of the leading three countries in GDPPC (whichever they were) from 1700 to 2018. The point of this graph (which is a variant on the “hockey stick” graphs that illustrate the consequences of the acceleration of economic growth that began sometime in the 19th century and has been sustained in the OECD countries at roughly 2 ppa) is that many countries in the world today are still at levels of GDPPC that the now advanced countries had a century or more ago. Twenty nine countries had GDPPC in 2018 lower than the most advanced countries had in 1700. Another nineteen countries have GDPPC lower than the leading countries had in 1870.
And the poorer countries in the world today are not that much higher than the GDPPC that the leading countries had 2000 or 1000 years ago. Niger is estimated to have lower GDPPC in 2018 than Egypt has in 1 CE. Ethiopia’s GDPPC, at M$1838 (M$ for the Maddison PPP units) is only about 50 percent above where China was in 1000 CE.
This is just important factual context as it is obviously one thing to debate how much a priority economic growth is when GDPPC is M$40,000 or more (Japan, Germany (DEU), USA) than if one is at the levels of India or Vietnam (M$6800) or less. Even China or Indonesia, countries that have obviously had extended periods of rapid growth are still only at the level the leading countries had in 1950. Clearly how much more economic growth is a priority depends on how much one has had.
The second key graph, and the key point of the paper, is that if one constructs any index of the basics of human material wellbeing not from economic output measures but from physical indicators like health, education, water and sanitation, nutrition, environment it is very tightly associated with GDPPC in a non-linear way. As countries move from low levels of GDPPC to levels up to about P$ 25,000 (about where Argentina and Chile are) the extent to which basic human needs are met increases very steeply. After that, and in particular for the top quartile of countries (above P$38,637, where P$ is the Penn World Tables PPP measure) there is little gain to basics–because the level of basics is very high.
And what the paper demonstrates at some length is that this strong, non-linear association of GDPPC and basics is robust to any plausible definition of “basics.” That is, if one constructs a multi-dimensional measure of basics of human wellbeing it doesn’t really matter which exact variables one includes or the weights one uses to add the indicators up, you get roughly the same results. So the claim is not that GDPPC and “a” measure of basics are related strongly and non-linearly, the claim is that this is true of “any” measure of basics.
The reason I wrote this paper is not that I want to weigh in about what priority should be placed on economic growth in the USA or Germany or New Zealand or the UK. they have a lot of it. But my worry is that the Golden Rule, that one should “do unto others as you want have them do unto you” can be confused between “preferences” and “priorities.” The debate about what development agencies like the World Bank or IADB or the bilateral development agencies of OECD countries might be influenced by thoughts of the type “Since we want in our own domestic affairs a lower priority on economic growth, development agencies should put less weight on economic growth.” But the Golden Rule has to be applied by asking “what would I want if I had my preferences and a given set of circumstances, like how much I already have of the various things I want.”
As we know from Engel’s law, when people have low levels of income their share of spending on food is very high (70 percent or more) and when people have very high levels of income their sharing of spending on food is more like 7 percent. This is not because preferences change but because priorities change and when one gets more food it becomes, at the margin, less of a priority. But obviously the Golden Rule conclusion for a rich person is not “since food is not a priority for me it is not a priority for others so I won’t worry about food consumption as a priority.”
This is part of a broader argument of mine that we need to keep economic growth (“gold”) in the Golden Rule of what development agencies see as their role to help poorer countries (and societies and households) achieve the levels of economic productivity that are essential to provide their populations with the basics–even if that, thankfully, is no longer a priority for prosperous places.
I have a new draft paper drafted as a handbook volume on “Development and Aid” being edited by Shanta Devarajan, Jennifer Tobin, and Raj Desai at Georgetown. The paper kind of builds on an earlier blog of mine The Perils of Partial Attribution in which I worry that people sometimes get confused about the facts and the counter-factual. The title of the paper is: “Development Happened. Did Aid Help?” (This is the version as of February 2024).
An organizing analogy is the Belichick-Brady debate. The fact is that the team they were both affiliated with, the New England Patriots, had one of the most impressive and successful periods of any major sports franchise, ever, winning 6 Super Bowls. One then might want to parse out some causal attribution of how much of this success was due to Bill Belichick as coach and how much was due to Tom Brady as quarterback. And so on imagines an alternative world in which Tom Brady had played for another team with an average (sequence of) coaches or that Bill Belichick had coached with a sequence of quarterbacks.
The difficulty with the development-aid debate outside of the realm of development experts is that, as Hans Rosling so gently puts it, the “person on the street” in a rich country knows less about conditions in developing countries than a monkey, because at least a monkey doesn’t know stuff that is wrong.
Something like 85 percent of Americans thought global poverty over recent decades had either “stayed about the same” or “risen.” This is like trying to engage in the Brady-Belichick debate with someone who says “Well, we know neither can be so terrific because their team never won a Super Bowl.” Well, no, that is actually not up for debate as that is a fact, a given, something that everyone agrees actually happened. The only question is what causally explains that fact.
If you believe, wrongly, that “development didn’t happen” then it is easy to think “well, since ‘aid’ was supposed to promote development and development didn’t happen, aid (probably) didn’t work.” The conclusion is not necessary wrong, but the argument is just stupid because it starts from demonstrably incorrect assumptions about the facts.
Let’s not start the discussion of development success with economic indicators (like GDP per capita growth) as they are controversial and let’s not start with poverty, as that has so many definitions. Let’s start with a couple of things that pretty much everyone agrees with: that every child should go to school and that it is bad when children die. Turns out in the “development era” progress on those was amazingly fast.
The figure shows the average years of schooling of the adult population in the developing world in 1870, 1950 and 2010 (from Lee and Lee 2016 data). From all of human history to 1950 (however many thousands of years you want to call that) the cumulated gain in years of schooling in formal education was 1.58, with most people having had no schooling at all. By 2010 the average was 7.5 years, so that there was more gain in years of schooling in the sixty years from 1950 to 2010 than in all previous human history, by a factor of 3.7.
I am not saying that everything about this expansion of education was a success, and I am a big advocate of acknowledging and addressing the “learning crisis” that lots of kids are getting schooling with little or not learning, but still, this is a massive, historically transformative success to have moved from little or no schooling to pretty much universal access to primary schools in pretty much every country. Big win. Huge win.
And, as an interesting dimension of that expansion of schooling, one can run a simple bivariate regression of years of schooling on GDPPC in 1950 and then “predict” the level of schooling that would have resulting from economic growth alone, and, contrary to the idea that “development” focused on growth but not human development indicators, here the progress in years of schooling was substantially more than growth would have “predicted” not less.
Same things are true of child mortality. Under 5 child mortality (deaths per 1000 births) fell from 293 in 1950 to 32.6 in 2018 (using data from Gapminder). Again, more reduction in child deaths from 1950 to 2018 than in all of previous human history, by a factor of about 1.7. Big win. Huge win.
So the question has to be: “What accounts for this enormous progress in a wide array of indicators of human wellbeing in the developing world in the development era?” It may be that aid played no role (or that it is just impossible to know with any confidence what role aid played as the right counter-factual just does not exist–as one suspects is the inevitable outcome of the Brady-Belichick debate) but at least let’s be smarter than monkeys about the actual facts that we are trying to understand and parse the causes of.